Descenso del gradiente: Regresión Lineal#
En esta sección vamos implementar varias versiones del algoritmo del descenso del gradiente para resolver el problema de la regresión lineal planteado en este ejercicio sin necesidad de usar una fórmula cerrada que nos da el valor óptimo de los parámetros del modelo.
Supongamos que tenemos un modelo de regresión capaz de estimar una variable objetivo \(y\) mediante un conjunto de parámetros \(\theta\)
y supongamos que queremos encontrar \(\hat{\theta}\) óptimo tal que \(C(\hat{y}, y)\) sea lo más pequeño posible, donde \(C\) es una función de coste a definir, como puede ser el error cuadrático medio (MSE). El algorimo del descenso del gradiente propone aproximar \(\hat{\theta}\) mediante los siguientes pasos
Inicializar de forma aleatoria \(\theta^0\).
Para cada \(i>0\), calculamos \(\theta^i\) como
donde \(\nabla\) es el operador gradiente y \(\eta\) es la tasa de aprendizaje o learning rate.
Regresión Lineal#
Consideremos ahora el problema de la regresión lineal, donde queremos inferir una relación lineal entre una variable objetivo \(y\) y un conjunto de variables regresoras \(x = (x_1, \dots, x_n)\) a partir de un conjunto de \(m\) observaciones \((x^1, y^1), \dots, (x^m, y^m)\)
y nuestra función de coste es el error cuadrático medio,
Para aplicar el algoritmo del descenso del gradiente, primero tenemos que calcular el gradiente de la función de coste respecto a los parámetros del modelo. Gracias a la simplicidad de nuestro modelo, podemos derivar directamente la fórmula para obtener
Si escribimos esta fórmula en su forma matricial, obtenemos
donde
Implementemos el algoritmo del dencenso de gradiente en Python usando Numpy. Para ello necesitamos algunos hiperparámetros
El número de iteraciones del algoritmo:
n_iter,La tasa de aprendizaje:
eta
Exercise 65
Crea una clase RegresionLinealDG con 3 métodos:
__init__: inicializa los atributoseta,n_iteral crear instancias. Usar valores por defectoeta=0.1,n_iter=1000.entrena: toma como inputs un arrayXde dimensión(m, n)eyde dimensión(m,), dondemrepresenta el número de observaciones totales ynes el número de variables regresoras. Generaun atributo
thetasque será una lista donde se guarden arrays de dimensiónnrepresentando cada una de las iteraciones del algoritmo de descenso del gradiente.otro atributo
costesque será una lista donde se guarden cada uno de los valores de la función de coste en cada iteración del algoritmo.
predice: tomo como input un arrayXde dos dimensiones, cuya segunda dimensión esny utiliza el último elemento dethetaspara realizar predicciones según nuestro modelo lineal.
%config InlineBackend.figure_format='retina'
import numpy as np
import matplotlib.pyplot as plt
class RegresionLinealDG:
def __init__(self, eta=0.1, n_iter=1000):
self.eta = eta
self.n_iter = n_iter
self.rng = np.random.default_rng()
def entrena(self, X, y):
m, n = X.shape
X_ones = self.añade_unos(X)
self.thetas = [2*self.rng.random(n + 1) - 1]
self.costes = [self.f_coste(X_ones, y, self.thetas[-1])]
for iter in range(self.n_iter):
theta = self.thetas[-1] - self.eta*self.calcula_grad(X_ones, y, self.thetas[-1])
self.thetas.append(theta)
self.costes.append(self.f_coste(X_ones, y, self.thetas[-1]))
def añade_unos(self, X):
m = X.shape[0]
X_ones = np.concatenate([np.ones((X.shape[0], 1)), X], axis=1)
return X_ones
def f_coste(self, X, y, theta):
m = X.shape[0]
cost = np.mean((X @ theta - y)**2) / m
return cost
def calcula_grad(self, X, y, theta):
m = X.shape[0]
grad = X.T @ (X @ theta - y)* 2 / m
return grad
def pinta_datos(self, X, y, ax):
n = X.shape[1]
x1 = X[:, 0]
if n == 1:
self.pinta_datos2d(x1, y, ax)
elif n == 2:
x2 = X[:, 1]
self.pinta_datos3d(x1, x2, y, ax)
else:
return None
ax.set_title("Convergencia modelo")
ax.grid()
ax.legend()
return ax
def pinta_datos2d(self, x, y, ax):
ax.scatter(x, y, marker="o", label="datos")
x_min, x_max = x.min(), x.max()
x_sample = [x_min, x_max]
for iter in range(0, self.n_iter + 1, self.n_iter // 10):
theta = self.thetas[iter]
y_sample = [theta[0] + theta[1]*x_min, theta[0] + theta[1]*x_max]
ax.plot(x_sample, y_sample, label=f"iter {iter}")
ax.set_xlabel("$x_1$")
ax.set_ylabel("$y$")
return ax
def pinta_datos3d(self, x1, x2, y, ax):
x1_min, x1_max = x1.min(), x1.max()
x2_min, x2_max = x2.min(), x2.max()
x1_sample = np.linspace(x1_min, x1_max, 100)
x2_sample = np.linspace(x2_min, x2_max, 100)
X1, X2 = np.meshgrid(x1_sample, x2_sample)
for iter in range(0, self.n_iter + 1, self.n_iter // 3):
theta = self.thetas[iter]
Y = theta[0] + theta[1]*X1 + theta[2]*X2
ax.plot_surface(X1, X2, Y, alpha=.3)
ax.scatter(x1, x2, y, marker="o", color="r", s=100, label="datos")
ax.set_xlabel("$x_1$")
ax.set_ylabel("$x_2$")
ax.set_zlabel("$y$")
return ax
def pinta_coste(self, ax):
ax.plot(self.costes)
ax.grid()
ax.set_xlabel("iteración")
ax.set_ylabel("coste")
ax.set_yscale("log")
ax.set_title("Convergencia función de coste")
return ax
def pinta_thetas(self, ax):
im = ax.scatter(
[theta[0] for theta in self.thetas],
[theta[1] for theta in self.thetas],
c = range(self.n_iter + 1),
marker="x"
)
ax.grid()
ax.set_xlabel("$\\theta_0$")
ax.set_ylabel("$\\theta_1$")
ax.set_title("Convergencia de $\\theta$")
ax = plt.colorbar(im, ax=ax)
ax.set_label("iteración")
return ax
def pinta(self, X, y):
fig, ax = plt.subplots(1, 3, figsize=(25, 8))
if X.shape[1] == 2:
# cambia la proyección del eje para hacer un
# plot en 3d si n = 2
ax[0].remove()
ax[0] = fig.add_subplot(1, 3, 1, projection='3d')
self.pinta_datos(X, y, ax[0])
self.pinta_coste(ax[1])
self.pinta_thetas(ax[2])
fig.suptitle(self.get_title())
return fig
def get_title(self):
return f"$\eta = ${self.eta}, n_iter = {self.n_iter}"
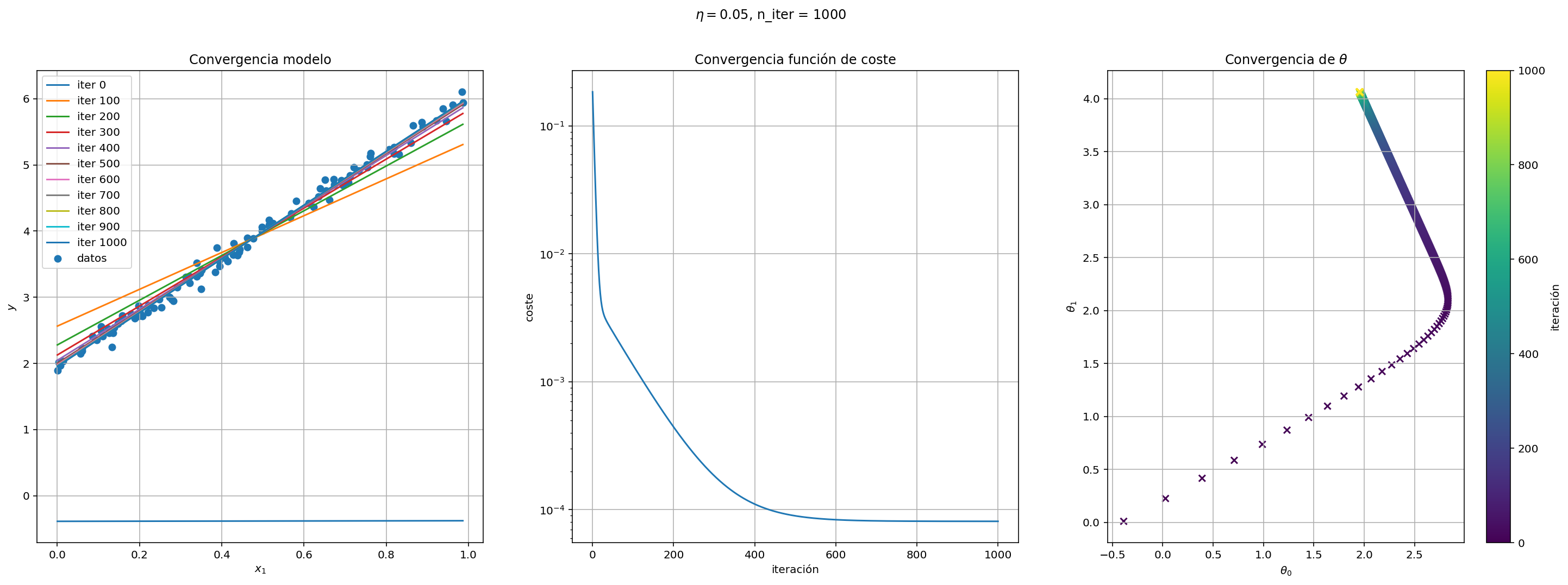
regresion_lineal_dg = RegresionLinealDG(eta=0.05)
rng_test = np.random.default_rng()
m, n = 100, 1
X_test = rng_test.random((m, n))
test_theta = rng_test.integers(2, 5, size=n)
y_test = 2 + X_test @ test_theta + 0.1*rng_test.standard_normal(m)
print(test_theta)
[4]
regresion_lineal_dg.entrena(X_test, y_test)
fig = regresion_lineal_dg.pinta(X_test, y_test)
Exercise 66
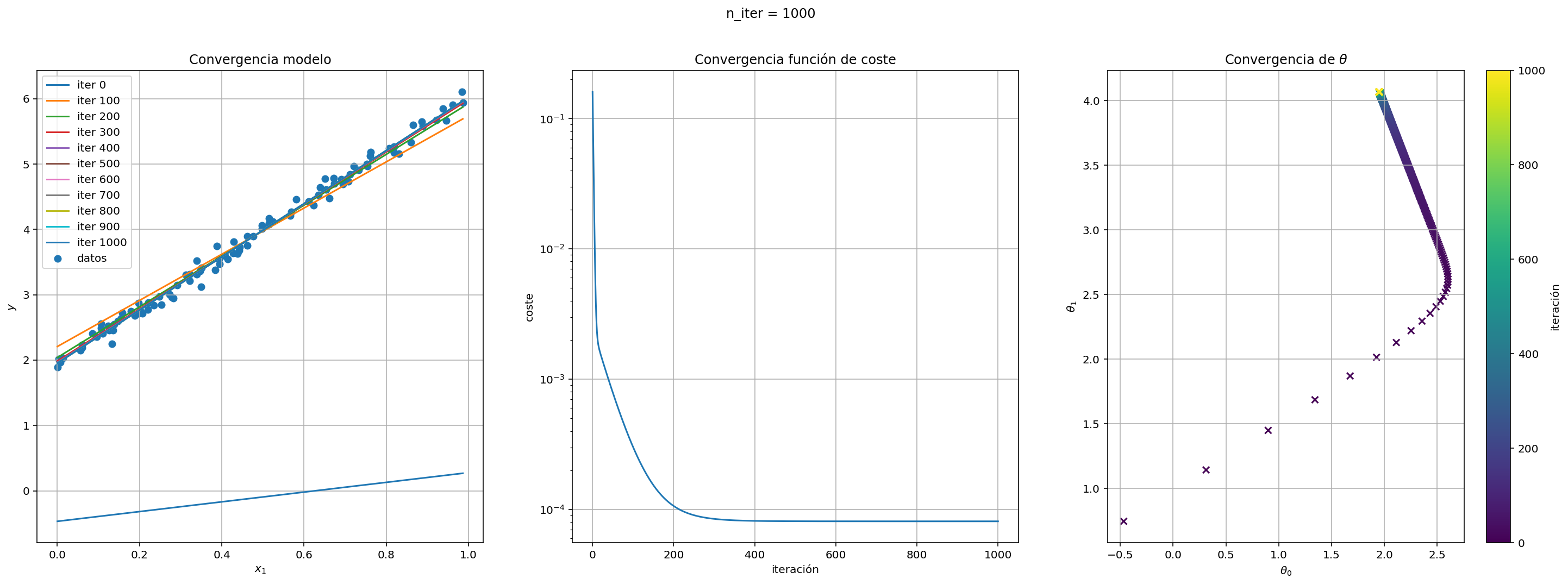
Implementa una clase que herede de la anterior en la que la tasa de aprendizaje eta sea una función decreciente de modo que vaya disminuyendo en el método entrena en cada iteración.
class RegresionLinealDG2(RegresionLinealDG):
def __init__(self, eta, n_iter=1000):
super().__init__(n_iter=n_iter)
self.eta = eta
def entrena(self, X, y):
m, n = X.shape
X_ones = self.añade_unos(X)
self.thetas = [2*self.rng.random(n + 1) - 1]
self.costes = [self.f_coste(X_ones, y, self.thetas[-1])]
for iter in range(self.n_iter):
theta = self.thetas[-1] - self.eta(iter)*self.calcula_grad(X_ones, y, self.thetas[-1])
self.thetas.append(theta)
self.costes.append(self.f_coste(X_ones, y, self.thetas[-1]))
def get_title(self):
return f"n_iter = {self.n_iter}"
eta = lambda x: 0.1*np.exp(-0.001*x)
regresion_lineal_dg2 = RegresionLinealDG2(eta)
regresion_lineal_dg2.entrena(X_test, y_test)
fig = regresion_lineal_dg2.pinta(X_test, y_test)
Exercise 67
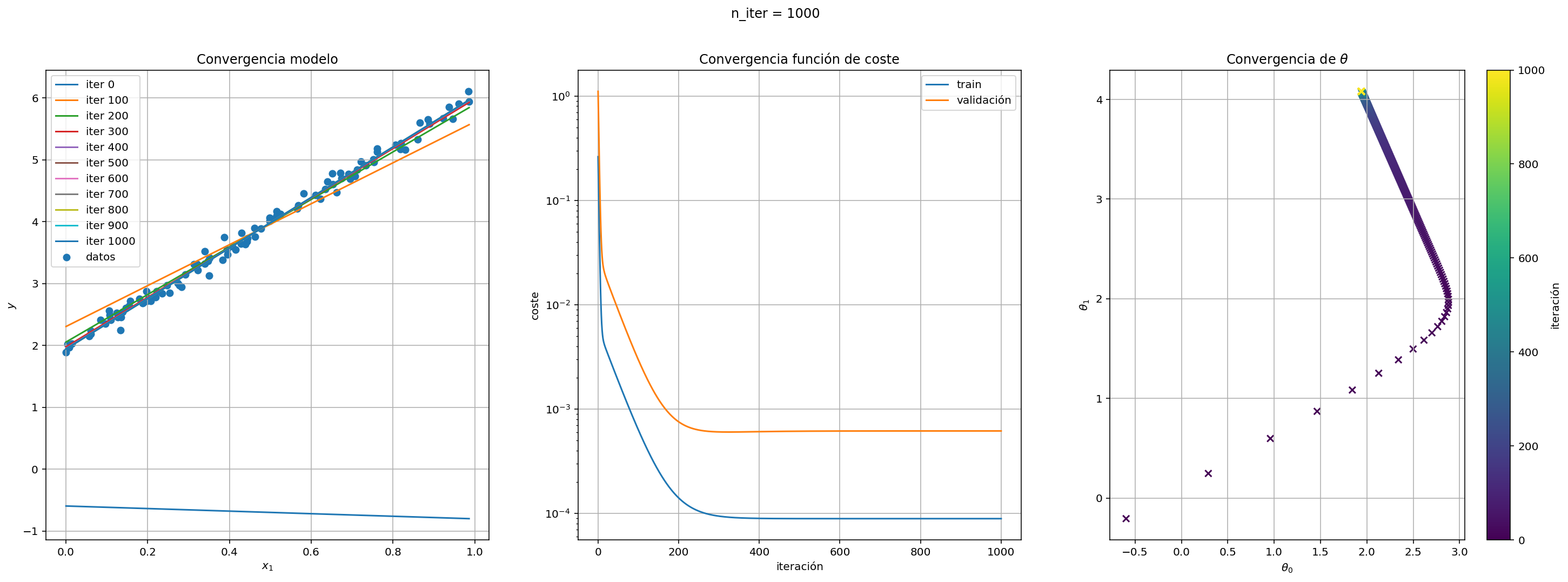
Mejora de nuevo la clase anterior para que reciba un parámetro booleano split (valor por defecto a True) de modo que cualdo split sea verdadero el conjunto de entrenamiento se divida de forma aletoria en dos partes, una con el 80% de los datos para ejecutar el algoritmo; otra con el 20% para validar y modificar los siguientes métodos:
entrena: además de generar los atributoscostes,thetas, generaremoscostes_valcon el valor de la función de coste en cada uno de las iteraciones del algoritmo.pinta_costepara pintar también la curva de la función de coste en el conjunto de validación.
class RegresionLinealDG3(RegresionLinealDG2):
def entrena(self, X, y):
X_train, X_val, y_train, y_val = self.separa_val(X, y)
super().entrena(X_train, y_train)
self.calcula_costes(X_val, y_val)
def separa_val(self, X, y, val_ratio=0.2):
m, n = X.shape
val_set_size = int(m*val_ratio)
index = self.rng.permutation(m)
index_train, index_val = index[val_set_size:], index[:val_set_size]
X_train, X_val = X[index_train], X[index_val]
y_train, y_val = y[index_train], y[index_val]
return X_train, X_val, y_train, y_val
def calcula_costes(self, X, y):
X = self.añade_unos(X)
self.costes_val = [self.f_coste(X, y, theta) for theta in self.thetas]
def pinta_coste(self, ax):
super().pinta_coste(ax)
ax.lines[-1].set_label('train')
ax.plot(self.costes_val, label="validación")
ax.legend()
return ax
regresion_lineal_dg3 = RegresionLinealDG3(eta=lambda x: 0.1*np.exp(-0.0001*x))
regresion_lineal_dg3.entrena(X_test, y_test)
fig = regresion_lineal_dg3.pinta(X_test, y_test)
Descenso del gradiente estocástico#
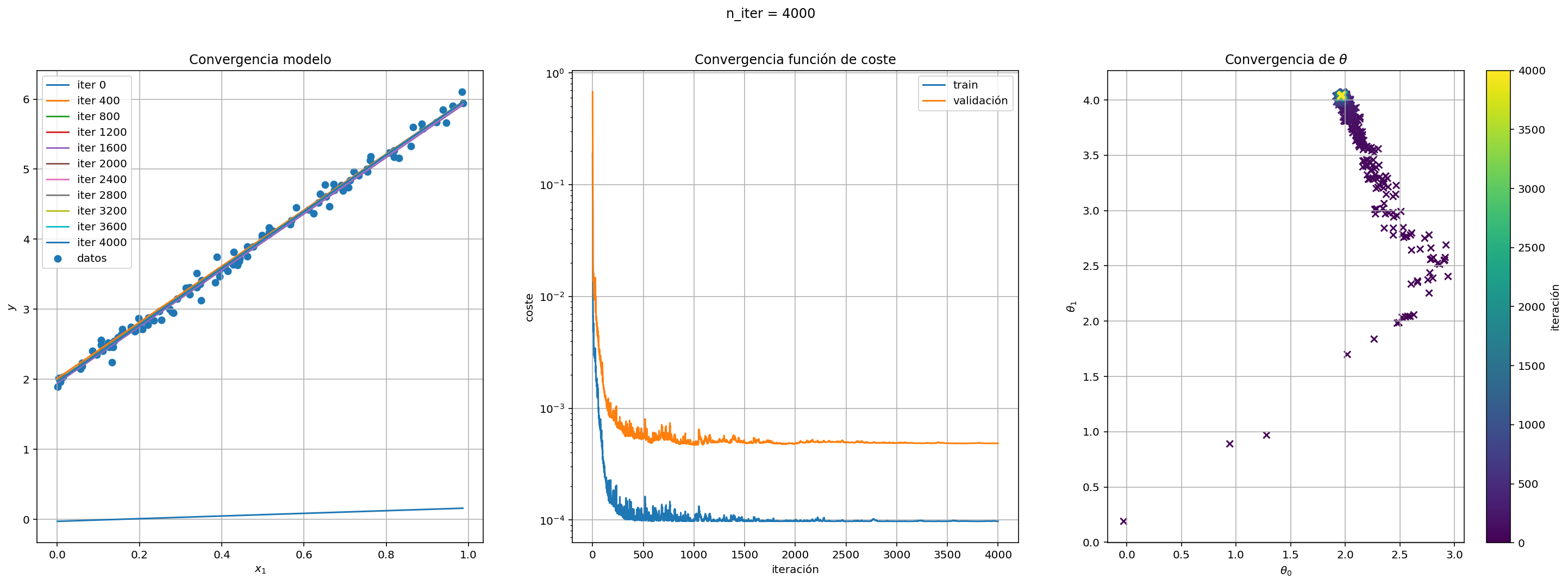
Si nos fijamos en la función de coste propuesta para el problema anterior, podemos ver que tiene tantos sumandos como observaciones tengamos en nuestro conjunto de entrenamiento y por lo tanto utilizamos todo el conjunto entero en cada paso del algoritmo, lo cual puede tener un gran coste computacional si el número de observaciones crece considerablemente.
Otra alternativa posible es considerar solamente la contribución de una observación del conjunto de set a la hora de calcular el gradiente. En este nuevo enfoque, denominado descenso estocástico del gradiente, recorremos el conjunto de train varias veces eligiendo elementos al azar (con remplazamiento). Cada una de las iteraciones que hacemos sobre el conjunto de train al completo se denominan épocas. Cuando utilicemos descenso del gradiente estocástico, es importante que la tasa de aprendizaje vaya siendo cada vez más pequeña, sobre todo cuando nuestro función de coste tenga mínimos locales.
Exercise 68
Crea una clase que herede de RegresionLinealDG3 denominada RegresionLinealDGE para implementar el algoritmo de descenso de gradiente estocástico en lugar del dencenso del gradiente convencional. Deberá aceptar un argumento en su __init__ que sea n_epocas
class RegresionLinealDGE(RegresionLinealDG3):
def __init__(self, eta, n_epocas=50): # quitamos n_iter
super().__init__(eta=eta, n_iter=None)
self.n_epocas = n_epocas
def entrena(self, X, y):
X_train, X_val, y_train, y_val = super().separa_val(X, y)
self.n_iter = self.n_epocas * X_train.shape[0]
self.entrena_estocastico(X_train, y_train)
super().calcula_costes(X_val, y_val)
def entrena_estocastico(self, X, y):
m, n = X.shape
X = self.añade_unos(X)
self.thetas = [2*self.rng.random(n + 1) - 1]
self.costes = [self.f_coste(X, y, self.thetas[-1])]
for epoca in range(self.n_epocas):
for i in range(m):
index = self.rng.integers(m)
X_sample = X[index:index+1]
y_sample = y[index:index+1]
theta = self.thetas[-1] - self.eta(epoca*m + i)*self.calcula_grad(X_sample, y_sample, self.thetas[-1])
self.thetas.append(theta)
self.costes.append(self.f_coste(X, y, self.thetas[-1]))
regresion_lineal_dge = RegresionLinealDGE(eta=lambda x: 0.1*np.exp(-0.001*x))
regresion_lineal_dge.entrena(X_test, y_test)
fig = regresion_lineal_dge.pinta(X_test, y_test)
Exercise 69
En realidad lo que se suele emplear es una solución intermedia entre el descenso del gradiente estocástico y el estándar, denominada descenso del gradiente a tramos o mini-batch gradient descent. La idea es similar al descenso del gradiente estocástico, salvo que en lugar de tomar una observación en cada iteración, tomamos un conjunto o batch de estas, pero no el dataset entero.
Crea una clase RegresionLinealDGMB que implemento el descenso del gradiente a tramos.